
張學鋒1, 聞亦昕1, 熊大林2, 龍紅明3
(1.安徽工業(yè)大學計算機科學與技術學院,安徽 馬鞍山 243032; 2.首鋼自動化信息研究院,河北唐山 063000; 3.安徽工業(yè)大學冶金工程學院,安徽 馬鞍山 243032)
摘 要:針對燒結工藝 FeO 預測準度問題,提出一種基于機器學習的預測模型。通過對機尾斷面溫度數(shù)據(jù)的采集和處理,建立包含多個特征的數(shù)據(jù)集。采用基于 MIV(平均影響值)的特征選擇方法,篩選出對預測模型權重占比較高的特征。使用 Bi-LSTM(雙向長短時記憶神經(jīng)網(wǎng)絡)算法對生產(chǎn)工藝數(shù)據(jù)進行訓練和測試,得到高精度的預測模型。通過實驗驗證了該模型的預測效果,并與其他神經(jīng)網(wǎng)絡模型方法進行了比較,比較結果表明該模型具有較高的預測精度和實用性。在企業(yè)誤差允許的范圍內(nèi),準確率達90.2%,因此可以為智能燒結技術的應用和燒結質(zhì)量的控制和優(yōu)化提供重要的參考。
關鍵詞:智能燒結;預測模型;燒結礦 FeO 含量;大數(shù)據(jù);神經(jīng)網(wǎng)絡
中國大多數(shù)鋼鐵企業(yè)都配備了完整的燒結等煉鐵工藝數(shù)據(jù)采集和存儲系統(tǒng)[1]。系統(tǒng)中積累了大量 燒結生產(chǎn)數(shù)據(jù),但相關數(shù)據(jù)尚未得到充分挖掘與分析。在大數(shù)據(jù)智能技術的高速發(fā)展背景下,研究人員可以利用機器學習、深度學習等方法分析燒結工藝數(shù)據(jù)并發(fā)掘其相關性,將大數(shù)據(jù)智能化技術與冶金理論和燒結生產(chǎn)經(jīng)驗深度融合[2]。本研究旨在面向智能燒結的機尾斷面燒結礦 FeO 預測展開深入研究。如今鋼鐵企業(yè)對于燒結礦 FeO含量的判斷與檢測已愈發(fā)自動化與智能化[3]。然而,由于燒結現(xiàn)場環(huán)境差、信息延遲等因素,燒結礦中 FeO 含量測定結果的準確性和穩(wěn)定性不夠,給燒結過程的及時控制帶來了巨大困難。根據(jù)燒結過程的原理和經(jīng)驗,燒結機尾斷面的溫度特征信息與燒結礦質(zhì)量及 燒結礦 FeO 含量密切相關[4]。眾多研究證明紅火層的分布情況、氣孔大小以及燒結礦輪廓等圖像特征信息與燒結礦特性息息相關,但燒結機尾斷面溫度分布特征與燒結礦特性之間存在更緊密的聯(lián)系[5]。想要精確地預測 FeO 的含量,需要更加智能的處理算法。
隨著大數(shù)據(jù)智能化技術的提高,各鋼鐵企業(yè)在提升產(chǎn)品質(zhì)量,降低工業(yè)成本等方面有了更新更高的要求。通過研究相關參考文獻發(fā)現(xiàn),唐玨等[6]學者在燒結系統(tǒng)全鏈條數(shù)據(jù)治理、智能配礦、燒結狀態(tài)質(zhì)量智能預測、燒結狀態(tài)質(zhì)量綜合評價與優(yōu)化等智能化燒結技術方面開展了系統(tǒng)工作。劉榮貴等[7]學者開發(fā) Web發(fā)布及云端交互子平臺實現(xiàn)了漣鋼所有鐵前工藝數(shù)據(jù)的移動互聯(lián)和云端處理。而在燒結過程中,FeO 的含量作為衡量燒結礦質(zhì)量的重要指標之一,除了對燒結礦的還原性和燒結過程的能耗產(chǎn)生影響之外,它還對高爐的間接還原和燃料比等方面有一定的影響。隨著大數(shù)據(jù)分析計算技術和人工智能技術的不斷進步,許多學者已經(jīng)開始采用機器學習等方法對燒結礦中的 FeO 含量進行預測,以實現(xiàn)科學指導生產(chǎn)的目標。 張智峰團隊[8]使用MIV-GA-BP神經(jīng)網(wǎng)絡模型對燒結礦中FeO 含量進行預測,在誤差 ±0.5% 的 范圍內(nèi)準確率達到87.9%。蔣朝輝團隊[9]提出基于模糊推理和 R-CLSTM 的燒結過程 FeO預測模型,能確保燒結過程平穩(wěn)運行。張樂文團隊[10]以加權支持向量機(WSVM)為基礎,提出了一種用于預測 FeO 含量和轉鼓指數(shù)的回歸估計方法,有利于技術人員對燒結過程做出合理的調(diào)控。吉訓生團隊[11]提出了一種改進的螢火蟲算法不僅提高了網(wǎng)絡學習的速度,還顯著提升了模型的預測精度。
本文提出一種通過獲取智能燒結系統(tǒng)中機尾紅外熱成像圖像并建立 Bi-LSTM 神經(jīng)網(wǎng)絡 FeO 預測模型。系統(tǒng)采集了大量的機尾斷面燒結礦溫度樣本數(shù)據(jù),并通過特征提取算法和分步模型構建,建立了準確可靠的燒結礦 FeO 預測模型。通過實驗與生產(chǎn)現(xiàn)場的調(diào)試使用證明了該預測模型是實現(xiàn)燒結礦FeO 含量預測的途徑之一。
1 數(shù)據(jù)分析
1.1 數(shù)據(jù)來源
燒結機尾斷面圖像蘊含了燒結豐富的信息[12], 如燒結礦 FeO 含量、轉鼓指數(shù)、垂直燒結速度及橫向的均勻性等,如果能有效提取并應用對燒結生產(chǎn)意義重大[13]。如圖1所示,在智能燒結系統(tǒng)中,機尾斷面紅外熱成像系統(tǒng)采用制冷型熱像儀熱圖像溫度采集單元,捕獲臺車在傾倒物料的整個周期中溫度最高的機尾斷面,隨后計算機圖像處理單元機尾斷面溫度數(shù)據(jù)進行處理,采用數(shù)字圖像處理技術,將溫度數(shù)據(jù)轉換成熱圖像并使其具有溫度特征。
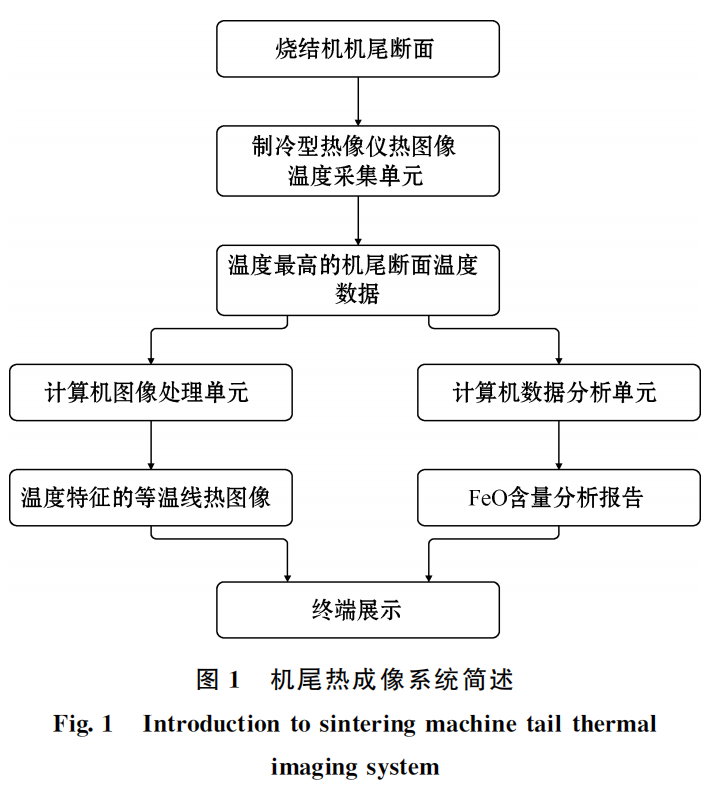
燒結礦斷面周期循環(huán),當最清晰完整斷面圖像呈現(xiàn)時,即認為該時刻斷面為最佳機尾斷面圖像出現(xiàn)時,因為燒結礦的卸下一瞬間是伴隨著復雜的物理化學變化的過程[14],在種種因素的影響下并不能保證剛好下落,時間方面可能提前也可能滯后,因此傳統(tǒng)根據(jù)標定臺車車輪在軌道上位置,臺車長度和運行速度計算出控制攝像選取斷面圖像的周期的方法并不適用現(xiàn)場生產(chǎn)環(huán)境。本文采用計算機尾運動斷面圖像序列差分的方法[15-16]選取最佳斷面。
由圖2所示,當最佳斷面捕獲成功后,分析得到機尾熱成像圖像的溫度數(shù)據(jù),由此獲得主要的機尾斷面特征參數(shù)有最高溫度、最低溫度、平均溫度以及間隔為100℃的溫度間隔區(qū)間占比。

1.2 數(shù)據(jù)處理
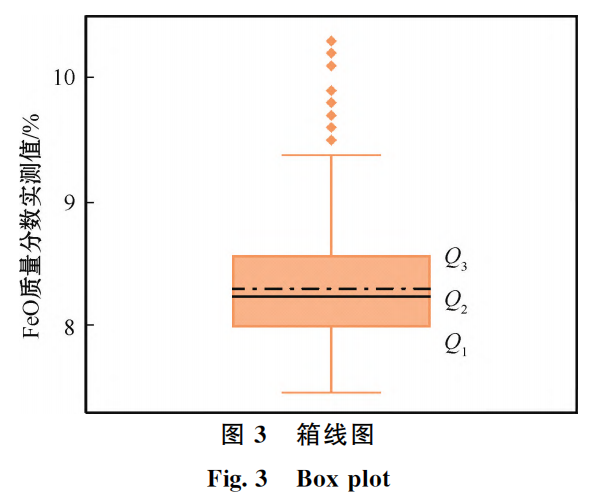
在日常企業(yè)生產(chǎn)中,生產(chǎn)人員每日使用化學檢測法檢測燒結礦 FeO 含量4~5次,并傳輸至系統(tǒng)后臺進行處理:將實測時間與最接近實測時間的溫度斷面數(shù)據(jù)形成對應并存儲,為模型的訓練做數(shù)據(jù)基礎。而企業(yè)生產(chǎn)數(shù)據(jù)雖然由自動裝置收集而成,但實際生產(chǎn)過程卻可能由于生產(chǎn)異常、停機檢修等情況產(chǎn)生損失信息的現(xiàn)象,所以須對異常信息值區(qū)分情況處理[17]。在異常值處理中,本文選擇采用箱線圖算法。
在圖3箱線圖中,異常值通常是指離群點(Outlier),即遠離箱體的數(shù)據(jù)點[18]。箱線圖中的“whisker”線條可以幫助識別異常值。箱線圖中的“whisker”線條通常被定義為1.5倍的四分位 距(Q3~Q1)或者2倍的標準差。超出這個范圍的數(shù)據(jù)點被認為是異常值[19]。在本研究中,設定箱線圖中的“whisker”線條定義為1.5倍的四分位距,那么位于上下“whisker”之外的數(shù)據(jù)點被認為是異常值。在這種情況下,若數(shù)據(jù)點的值大于 Q3 +1.5× (Q3-Q1)或者小于Q1 -1.5×(Q3 -Q1),那么它就被認為是異常值[20]。需要注意的是,箱線圖只能幫助初步識別異常值,并不能確定它們是否真的是異常值。如果遇到異常值,需要仔細檢查數(shù)據(jù)的來源和收集方式,以確定它們是否真正反映了數(shù)據(jù)的異常情況。因此,研究中將箱線圖處理結果與現(xiàn)場工作人員的生產(chǎn)經(jīng)驗相結合最終得到目標數(shù)據(jù)。
1.3 特征選擇
MIV 算法是一種特征選擇算法,用于從大量特征中篩選出最有價值的特征。它主要用于決策樹算法中,通過計算每個特征對決策樹劃分的貢獻來評估特征的重要性,然后選擇最重要的特征作為劃分依據(jù)[21]。MIV 算法的核心思想是通過計算特征在決策樹中的信息增益,來評估特征的重要性。信息增益表示在給定特征的條件下,將樣本集分成不同類別所獲得的信息量。如果一個特征的信息增益越大,則說明它對決策樹的劃分越有價值,也就越重要。
具體計算過程如下:
(1)使用原始數(shù)據(jù)訓練一個正確的神經(jīng)網(wǎng)絡。
(2)在訓練完成后,對訓練X中的各個指標數(shù)據(jù)加和減10樣 % 本 ,形 X成進2行個變新動的 ,將樣本 X1和 X2。
(3)將 X1和 X2重新輸入到訓練完成的神經(jīng)網(wǎng)絡中,得到變動后的2種結果 P1和 P2。輸出 (4)求 P1和 P2的差值,為變動該自變量后對產(chǎn)生的影響變化值。
(5)將變化應變 值按觀測例數(shù)平均得出該自量對于量的 MIV 值。
根據(jù)各特征參數(shù) MIV值(表1)的參考,結合多實驗結果最終選定 400~500℃,700~800℃, 900~1000℃,最高溫度,800~900℃與平均溫度作 為輸入特征進行構建模型。

2 模型構建
2.1 LSTM 算法
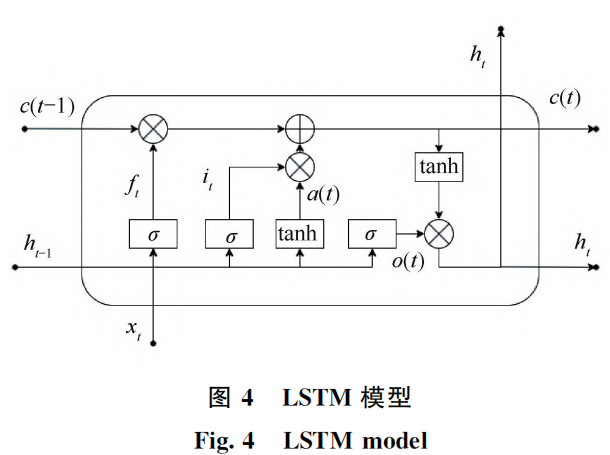
燒結機的連續(xù)產(chǎn)出性與各臺車布料參數(shù)彼此關聯(lián)的特性,說明預測燒結礦中 FeO 的含量是一個時間序列預測問題。LSTM長短期記憶網(wǎng)絡 (Lon Short-Term Memory)是一種適合處理時間序列數(shù)g據(jù)的強大模型(圖4),因此在預測燒結礦 FeO 含量時選用 LSTM 是合理的選擇。相較于其他訓練模型,有如下優(yōu)勢。
處理時間依賴性:LSTM 通過其內(nèi)部的記憶單元和門控機制能夠捕捉到時間序列中 FeO 含量之間的長期依賴關系,從而更好地進行預測[22]。
處理序列的動態(tài)模式:燒結礦中的 FeO 含量可能存在一些復雜的時間動態(tài)模式,如季節(jié)性變化、趨勢或周期性變化等[23]。LSTM 具有較強的非線性建模能力,可以適應并捕捉這些動態(tài)模式。
長期記憶能力:LSTM 可以通過門控機制選擇性地保留和遺忘信息,使得長期 FeO 含量能夠在預測中得到有效利用。
處理變長序列:燒結礦生產(chǎn)中可能存在不同時間段的數(shù)據(jù)采樣間隔不一致的情況,導致產(chǎn)生不同長度的時間序列數(shù)據(jù)。LSTM 因其計算過程是逐步進行的,不依賴于固定的輸入長度[24]從而能夠處理變長序列,這使得 LSTM 在處理具有不同時間間隔的燒結礦數(shù)據(jù)時非常適用。

式中:xt 為t時刻的輸入;ht-1 為t-1時刻的隱層狀態(tài)值;Wf、Wi、Wo 和Wa 分別為遺忘門、輸入門、輸出門和特征提取過程中ht-1 的權重系數(shù);Uf、Ui、Uo 和Ua 分別為遺忘門、輸入門、輸出門和特征提取過程中xt 的權重系數(shù);bf、bi、bo 和ba 分別為遺忘門、輸入門、輸出門和特征提取過程中的偏置值;σ為激活 函數(shù)Sigmoid。
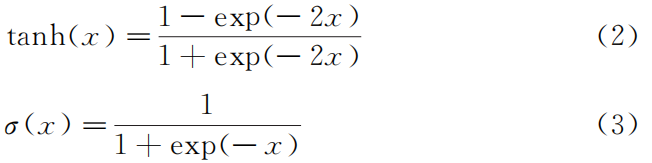
遺忘門和輸入門計算的結果作用于c(t-1 (3 ) ) , 構成t時刻的細胞狀態(tài)c(t),用公式表示為:
c(t)=c(t-1)☉f(t)+i
式中: (t)☉a(t) ☉ 為 Hadamard積。最終,t時刻的隱藏層狀態(tài)h(t)由輸出門o(t)和當前時刻的細胞狀態(tài)c(t) 求出:
![]()
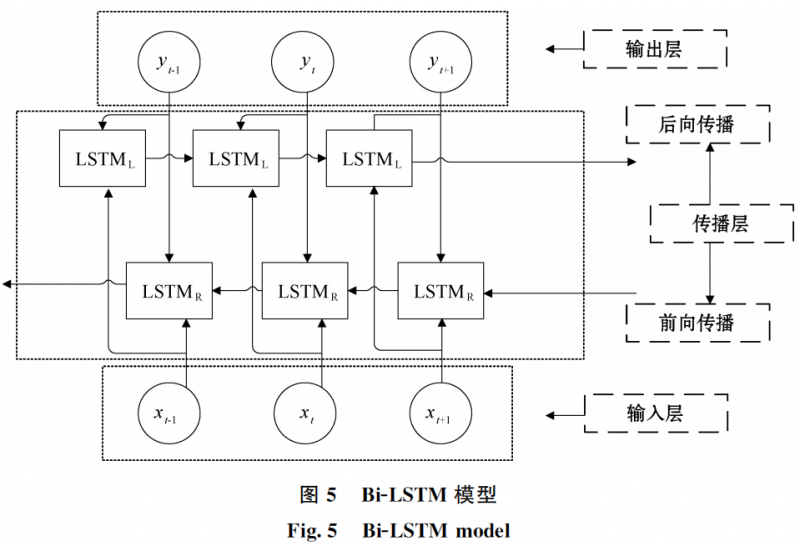
2.2 Bi-LSTM 模型
Bi-LSTM(雙向長短期記憶網(wǎng)絡)是一種深度學習模型,用于處理序列數(shù)據(jù),它是在傳統(tǒng)的 LSTM(長短期記憶網(wǎng)絡)基礎上發(fā)展而來的。在傳統(tǒng)的 LSTM 模型中,信息在序列中只能從過去傳遞到未來,即只有前向傳遞。 而如圖5所示的 BiLSTM 模型通過增加一個反向傳遞的分支,使信息 可以同時從過去和未來進行傳遞,這樣就能更全面 地捕捉序列數(shù)據(jù)中的上下文信息。Bi-LSTM 模型 的結構由2個 LSTM 組成,一個 LSTM 負責前向 傳遞,另一個 LSTM 負責反向傳遞。每 個 LSTM 單元都具有記憶單元和3個門控單元(輸入門、遺忘門和輸出門),以便控制信息的流動和記憶的更新。前向 LSTM 處理輸入序列的從頭到尾的順序,而后向 LSTM 處理輸入序列的從尾到頭的順序。通過前向和后向的信息流動,Bi-LSTM 模型能夠同時利用當前時間步之前和之后的信息,從而更好地捕捉序列中的時序關系和上下文信息[25]。 訓練BiLSTM 模型的過程通常涉及將輸入序列喂入網(wǎng)絡, 通過反向傳播算法來優(yōu)化模型的權重和參數(shù)。訓練完成后,該模型可以用于對新的序列數(shù)據(jù)進行預測, 以獲得特定任務的輸出[26]。
2.3 算法流程
根據(jù) B-LSTM 的特點,充分發(fā)揮其優(yōu)勢,BiLSTM 層用于學習序列學習塊中的長期時間信息, 最后在模型中疊加全連接層和輸出層,進行最終預測,從而提高模型的預測準確率。模型結構如圖6 所示,神經(jīng)網(wǎng)絡主要有6層包括輸入層、Bi-LSTM 層 (正向 LSTM 層、反向 LSTM 層)、全連接層、 Dropout層、全連接層和輸出層。

輸入層:將處理好的溫度相關數(shù)據(jù)作為 BiLSTM 層的輸入;
Bi-LSTM 層:該層由正向 LSTM和逆向 LSTM 組成,分別負責處理輸入序列的正向傳遞和輸入序列的反向傳遞;
全連接層:激活函數(shù)為Sigmoid;
Dropou層:按0.2比例進行隨機失活操作,防止神經(jīng)網(wǎng)絡模型過擬合; ,
輸出層:維度為1,輸出最終的預測結果。
長短時記憶網(wǎng)絡及其變體,具有長序列依賴性的能力。然而,長序列可能導致梯度消失或梯度爆炸問題,從而影響訓練的穩(wěn)定性和效率。因此,針對Bi-LSTM 神經(jīng)網(wǎng)絡的缺點,還需要改進以下2個方面:優(yōu)化算法與早停策略。
(1)AdaDelta優(yōu)化算法是一種自適應學習率的優(yōu)化算法,旨在解決傳統(tǒng)隨機梯度下降(SGD)中學習率難以確定的問題,并且能夠緩解梯度消失和爆炸問題[27]。算法核心思想是自適應地調(diào)整學習率,使得每個參數(shù)的更新步長可以根據(jù)梯度的歷史信息來自適應地調(diào)整。該算法通過維護2個累積平均值來調(diào)整參數(shù)的更新步長。一個是平方梯度的指數(shù)移動平均(稱為accumulatedgradient),另一個是參數(shù)更新步長的指數(shù)移動平均 (稱為 accumulatedupdate)。這2個累積平均值使得更新步長可以根據(jù) 梯度和參數(shù)歷史信息來動態(tài)地進行調(diào)整[28-29]。優(yōu)化過程如下。
1)初始化參數(shù):
初始模型參數(shù)θ; 積累梯度平方的指數(shù)衰減平均值E[g 2]; E[Δθ 積累參數(shù)更新量平方的指數(shù)衰減平均值 2]; 超參數(shù)ρ(控制衰減率); 微小常數(shù)ε(防止除以0)。
2)對于每個訓練批次(mini-batch),執(zhí)行以下步驟:
計算梯度g 關于當前批次的損失函數(shù);
更新參數(shù):
(a)計算梯度平方的指數(shù)衰減平均值,E[g 2]= ρ·E[g 2]+ (1-ρ)·g2。
(b)計算參數(shù)更新量,
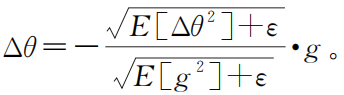
(c)計算參數(shù)更新量平方的指數(shù)衰減平均值, E[Δθ2]=ρ·E[Δθ2]+ (1-ρ)·Δθ2。
(d)更新參數(shù),θ=θ+Δθ。
(2)基于驗證集損失函數(shù)的早停策略用于監(jiān)模型測在訓練集上的損失函數(shù)值,當損失函數(shù)值連續(xù)若干次迭代沒有顯著改善或開始上升時,停止訓練。
基于驗證集指標的早停策略用于監(jiān)測除損失函數(shù)和精度外其他指標,當指標連續(xù)若干次迭代沒有顯著 改善或開始下降時,停止訓練[30]。研究中將可用的數(shù)據(jù)集劃分為訓練集、驗證集和測試集。訓練集用于模型的參數(shù)更新,驗證集用于評估模型的性能和監(jiān)測早停策略,測 試集用于最終評估模型的泛化能力。
1)定義均方
誤差損失函數(shù):
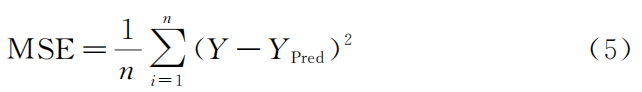
式中:n 為樣本數(shù)量;Y 為第i個樣本的實測值; YPred 為模型對第i個樣本的預測值。
2)初始化模型參數(shù):隨機初始化模型的循環(huán)權重參數(shù)、偏置參數(shù)等。
3)進行迭代訓練:在訓練集上進行模型的迭代訓練。每個訓練迭代中,使用訓練集的一批樣本進行前向傳播和反向傳播,更新模型的參數(shù)。
4)在驗證集上評估模型:每個訓練周期使用當前模型在驗證集上進行評估。計算模型在驗證集上的損失函數(shù)值和精度指標。
5)監(jiān)測驗證集損失函數(shù)與精度指標:比較當前的驗證集損失函數(shù)值與之前的最佳損失函數(shù)值。如果當前損失函數(shù)值較低,則更新最佳損失函數(shù)值,并保存當前模型的參數(shù)。同理比較驗證集指標值。若當前 6 指 ) 標值較高則更新最佳指標值并保存。
設定早停條件:連續(xù)迭代中驗證集損失函數(shù)值沒有顯著改善或開始上升,以及驗證集指標值沒有顯著改善或開始下降。當早停條件滿足時,停止訓練。
通過組合使用2種早停策略,可以綜合考慮模型的損失函數(shù)和其他重要指標,從而更準確地判斷模型的性能和泛化能力。
圖7算法結束后,將訓練好的模型添加至智能燒結系統(tǒng)中,現(xiàn)場采集數(shù)據(jù)后進行傳輸實現(xiàn)實施預測,并根據(jù)長期的預測命中率定期使用新的或擴展的數(shù)據(jù)重新訓練模型。
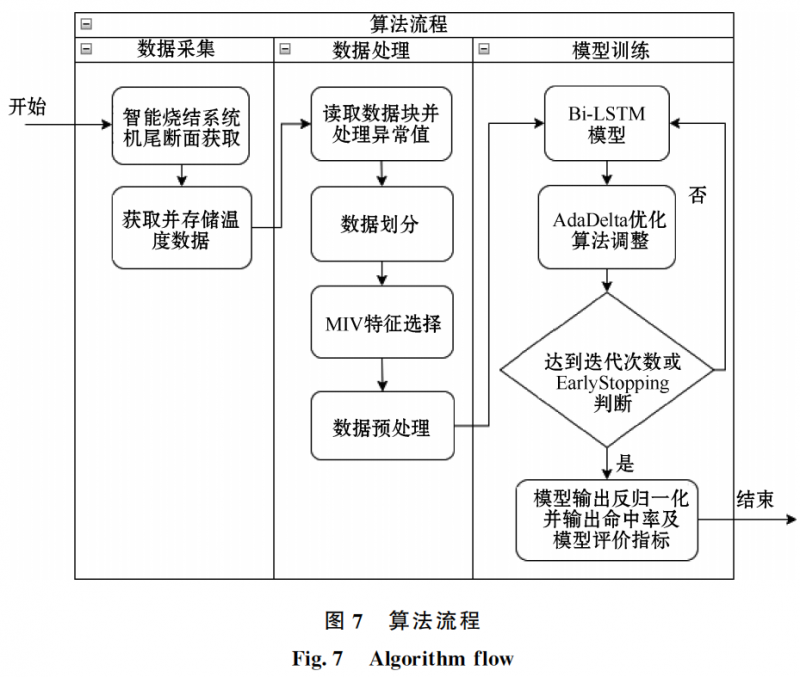
3 實驗結果與分析
本文研究中,所有實驗數(shù)據(jù)均來源于某燒結廠燒結機2022年3月11日至12月13日的1245組生產(chǎn)樣本。該數(shù)據(jù)樣本經(jīng)過數(shù)據(jù)清理,過濾空值樣本,箱型圖異常值處理等操作,最終剩余653組模型訓練樣本數(shù)據(jù)。
實驗中,所有樣本數(shù)據(jù)被隨機分為3部分:練習集,驗證集和測試集,比例為7.5∶1.5∶1.0。劃分完成后使用 Bi-LSTM 神經(jīng)網(wǎng)絡模型對練習集進行訓練,訓練完成后使用測試集來驗證訓練的有效性。
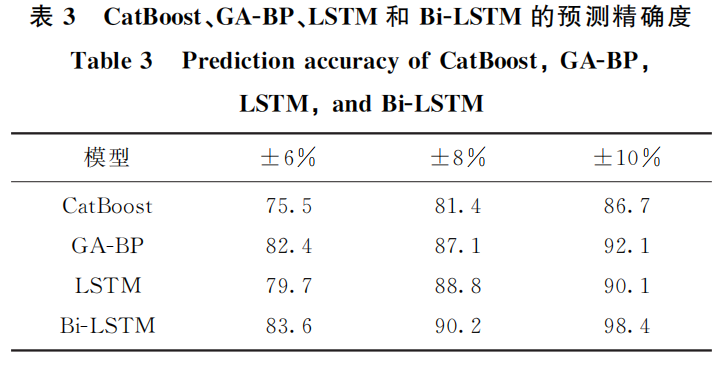
為驗證使用 Bi-LSTM 神經(jīng)網(wǎng)絡模型對燒結礦 FeO 含量的預測性能,本文還研究了其他相關神經(jīng)網(wǎng)絡 模型與該企業(yè)燒結礦數(shù)據(jù)的訓練學習預測性能。通過對比可知,Bi-LSTM 神經(jīng)網(wǎng)絡模型在均方誤差(MSE),均方誤差根 (RMSE),平均絕對誤差(MAE)均比其余網(wǎng)絡模型小(表2),說明該模型對燒結礦 FeO 含量的預測性能更佳。在各模型對比實驗 中 CatBoost模型[31]、BP 模型[32]、GA-BP 模型、GRU 模型和 LSTM 模型[33]均為相同參數(shù)條件下建立,且預測精度均達到75%以上。盡管各網(wǎng)絡模型都有較優(yōu)的訓練效果,但企業(yè)生產(chǎn)數(shù)據(jù)的數(shù)量與質(zhì)量,優(yōu)化算法的選擇和調(diào)參等各種因素會導致預測模型的準度下降。對此,本文所采用的 BiLSTM 模型,在性能方面,RMSE 等性能指標均為最優(yōu),在預測精確度方面也為最高,充分證明了該網(wǎng)絡模型與生產(chǎn)環(huán)境的適配性與高泛化能力。
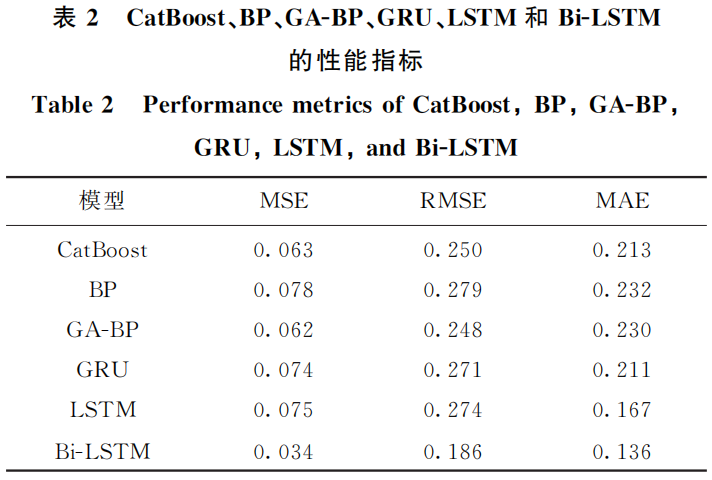
表3中,將性能較為優(yōu)良的模型進行訓練與測試,通過仿真及現(xiàn)場測試驗證,Bi-LSTM 模型在允許誤差±6%的條件下精確度可達83.6%,在允許誤差±8%的條件下精確度可達90.2%,在允許誤差±10%的條件下精確度可達98.4%。在相同的FeO 含量預測值與實際值規(guī)定誤差下,模型的預測準確率均高于其他實驗模型。
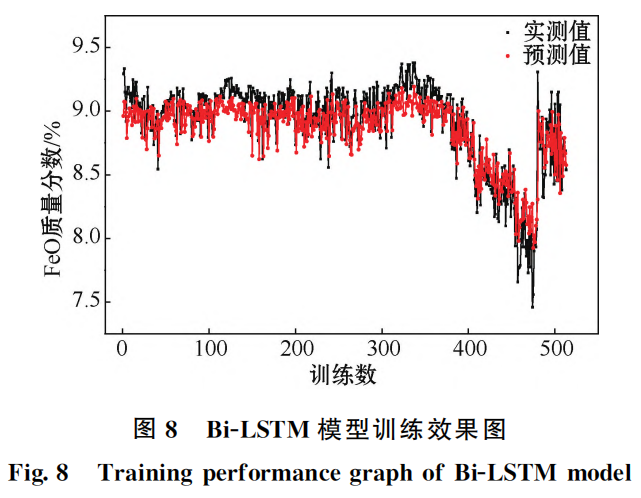
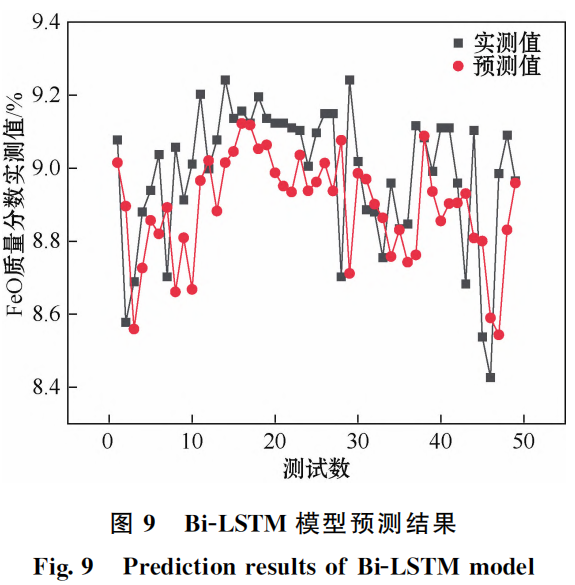
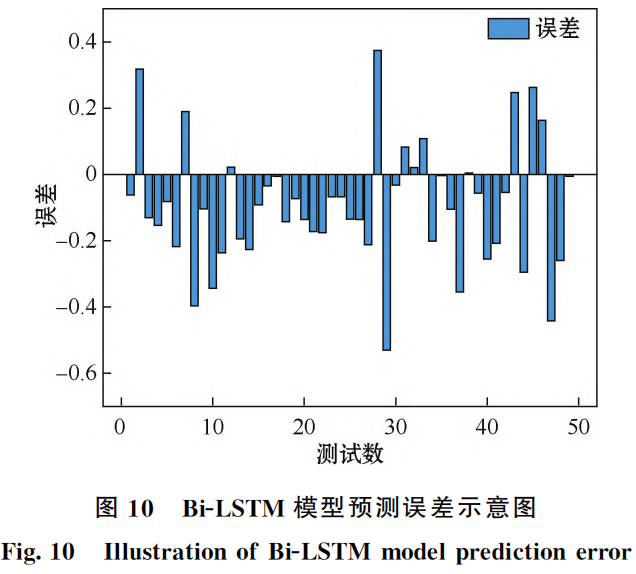
模型訓練過程以及測試集結果如圖8和圖9中給出。通過訓練效果圖可以觀察到模型在訓練數(shù)據(jù)上的表現(xiàn)逐漸提升,損失函數(shù)逐漸減小,這說明模型對訓練數(shù)據(jù)進行了有效的學習和擬合。通過預測結果圖可以觀察到模型在未見過的測試數(shù)據(jù)上能夠較為準確地預測且表現(xiàn)穩(wěn)定。結合圖10測試集誤差示意圖說明模型在泛化能力上表現(xiàn)良好,且在模型訓練測試中 Bi-LSTM 模型有著相當突出的優(yōu)勢與高吻合度。
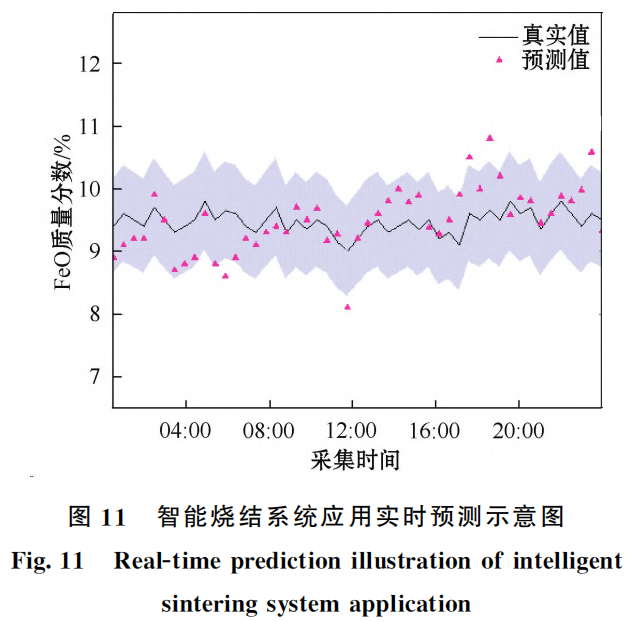
在智能燒結系統(tǒng)中,通過加載模型與傳輸數(shù)據(jù)達到實時預測的目的。圖11展示了模型與系統(tǒng)結合的實時預測效果,相較于以往建立的燒結終點預測模型,新的模型在預測準確率和穩(wěn)定性方面進一步提升。
4 結論與展望
(1)通過對機尾斷面燒結礦樣本的特征分析,發(fā)現(xiàn)機尾斷面相關溫度數(shù)據(jù)與 FeO 含量之間存在較為顯著的相關性。對于此非線性特征與 FeO 含量之間的關系,傳統(tǒng)的線性模型可能無法很好地捕捉到復雜的模式和依賴關系。在這種情況下,可以使用非線性模型來更好地建模和預測。
(2)本文研究基于 Bi-LSTM(雙向長短期記憶網(wǎng)絡)算法建立預測模型。為了進一步提高預測準確性,本文還引入了特征選擇和數(shù)據(jù)預處理技術。通過選擇關鍵特征和對數(shù)據(jù)進行歸一化處理,成功提高了預測模型的性能,并減少了模型的復雜度。該模型能夠高度準確地預測機尾斷面燒結礦的FeO 含量,并且具有較強的魯棒性和泛化能力。
(3)本文使用了大量的實驗數(shù)據(jù)對模型進行了驗證和評估。實驗結果表明,該預測模型在不同的機尾斷面燒結礦樣本上都具有較高的準確性和可靠性。這證明了該模型在實際應用中具有潛在的價值。
參考文獻:
[1] 楊聰聰,朱德慶,潘建,等.鐵礦石高溫燒結基礎特性評價方法的國外研究進展[J].鋼鐵,2022,57(5):11.
[2] 劉然,張智峰,劉小杰,等.基于工藝理論和卷積神經(jīng)網(wǎng)絡的燒結礦轉鼓指數(shù)預測[J].鋼鐵研究學報,2023,35(6):651.
[3] 項鐘庸,王筱留,顧向濤.再論落實高爐低碳煉鐵生產(chǎn)方針[J]. 中國冶金,2021,31(9):9.
[4] Li Y X,Yang C J,Sun Y X.Sintering quality prediction model based on semi-supervised dynamic time feature extraction framework[J].Sensors,2022,22(15):5861.
[5] Zhang N,Chen X L,Huang X X,et al.Online measurement method of FeO content in sinter based oninfrared machine vision and convolutional neural network[J].Measurement, 2022,202:111849.
[6] Li Z P,Fan X H,Chen G,et al.Optimization of iron ore sintering process based on ELM model and multi-criteria evaluation[J].Neural Computing and Applications,2017,28 (8):2247.
[7] 劉榮貴.漣鋼鐵前大數(shù)據(jù)平臺的開發(fā)與應用[J].中國鋼鐵業(yè), 2019(12):46.
[8] 張智峰,劉小杰,李欣,等.基于 MIV-GA-BP 模型預測燒結礦FeO 含量[J].中國冶金,2022,32(10):75.
[9] 蔣朝輝,黃良,蔣珂,等.基于模糊推理和 R-C-LSTM 的燒結過程 FeO 含量預測[C]//第32屆中國過程控制會議(CPCC)論文集.太原:中國自動化學會,2021:1575.
[10] 張樂文,陳新兵,侯東旭,等.基于加權支持向量機對燒結過程中 FeO 含量和轉鼓指數(shù)的預測研究[J].冶金動力,2017, 36(8):1.
[11] 吉訓生,荊田田,熊年昀.燒結礦 FeO 含量預測研究[J].計算機仿真,2015,32(10):318.
[12]Du S,Wu M,Chen X,et al.An in telligent control strategy for iron ore sinteringig nition process based on the prediction of ignition temperature[J].IEEE Transactions on Industrial Electronics,2020,67(2):1233.
[13] 余駿,孟飛,陳生利,等.FeO 含量對燒結礦冶金性能影響研究[J].礦業(yè)工程,2021,19(5):41.
[14] 熊大林,張功輝,余正偉,等.基于計算機視覺的燒結機尾斷面圖像研究進展[J].鋼鐵研究學報,2022,34(9):869.
[15] 鄭兆穎,邢相棟,王蓀璇,等.燒結礦低溫還原粉化率的影響因素及預測模型[J].燒結球團,2023,48(2):25.
[16] 吳海濱,楊西男,張樂文,等.一種燒結礦質(zhì)量判定系統(tǒng)的開發(fā)及應用[J].燒結球團,2018,43(4):6.
[17] 張振,李欣,劉頌,等.基于多類別生產(chǎn)狀態(tài)的燒結礦轉鼓指數(shù)預測模型[J].中國冶金,2022,32(1):27.
[18] 謝苗苗,李華龍.基于改進D-S證據(jù)理論的室內(nèi)環(huán)境控制決策系統(tǒng)[J].計算機工程與科學,2020,42(5):938.
[19] 史振杰,董兆偉,孫立輝,等.基于灰狼算法 SVR 的燒結礦 FeO 含量預測[J].河北省科學院學報,2019,36(4):1.
[20] 張兆磊.基于機器視覺的燒結礦FeO 含量判斷方法研究 [D]//沈陽:東北大學,2015.
[21] 劉丹,劉方,許彥平.基于 MIV-PSO-BPNN 的光伏出力短期預測[J].太陽能學報,2022,43(6):94.
[22] 孫勝博,吳彬彬,陳曄,等.雙通道多因素短期電力負荷預測模型[J].計算機工程與設計,2023,44(6):1875.
[23] Li Y X,Yang C J,Sun Y X.Dy namic time features expanding and extracting method for prediction model of sintering process quality index[J].IEEE Transactions on Industrial Informatics,2022,18(3):1737.
[24] Shao H J,Yi Z M,Chen Z,et al.Applicati on of artificial neural networks for prediction of sinter quality based on process parameters control[J].Transactions of the Institute of Measurement and Control,2020,42(3):422.
[25] Jiang Z H,GuoY H,PanD,etal.Polymorphic measurement method of FeO content of sinter based on heterogeneous features of infrared thermal images [J].IEEE Sensors Journal,2021,21(10):12036.
[26] ShaoC J,LiZ C,Guo C X.A novel method for online detection of FeO content in sinter[C]//2022International Conference on Artificial Intelligence and Computer Information Technology(AICIT).Yichang:IEEE,2022:1.
[27] Zhou P,Gao B H,Zhao C H,et al.Heterogeneous data-driven measurement method for FeO content of sinter based on deep learning and tensor decomposition[J].Control Engineering Practice,2023,134:105479.
[28] Usamentiaga R,Molleda J,Garcia D F,etal.Monitoring sintering burn-through point using infrared thermography [J].Sensors,2013,13(8):10287.
[29] 張劍,張燁.基于多特征融合的 GRU-LSTM 大學生就業(yè)動態(tài) 預測[J].計算機科學,2023,50(S1):906.
[30] Ding Q,Li Z P,Zhao L M.FeO content classification of sinter based on semi-supervised deep learning[C]//Proceedings of 2021 33rd Chinese Controland Decision Conference(CCDC). Kunming,China:IEEE,2021:640.
[31] Yuan X F,Gu YJ ,Wang Y L,et al.FeO content prediction for an industrial sintering process based on supervised deep belief network[J].IFAC-Papers On Line,2020,53(2):11883.
[32] 馬德剛,王耐,李建英,等.100t復吹轉爐冶煉IF鋼終點磷分 配比預測模型[J].煉鋼,2023,39(3):30.
[33] Jiang Z H,Huang L,Jiang K,et al.Prediction of FeO content in sintering process based on heat transfer mechanism and data-driven model [C ]//Proceedings of 2020 Chinese Automation Congress (CAC).Shanghai,China:IEEE, 2020:4846.